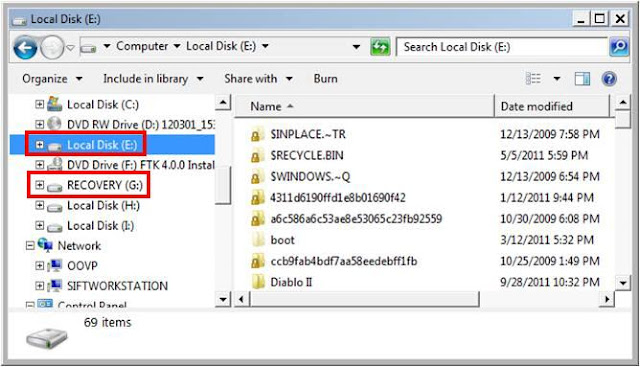
For the past few months I have been discussing a different approach to examining Volume Shadow Copies (VSCs). I’m referring to the approach as Ripping VSCs and the two different methods to implement the approach are the Practitioner and Developer Methods. The multipart Ripping VSCs series is outlined in the Introduction post. On Thursday (03/15/2012) I’m doing a presentation for a DFIROnline Meet-up about tracking user activity through VSCs using the practitioner method. The presentation is titled Ripping VSCs – Tracking User Activity and the slide deck can be found on my Google sites page.
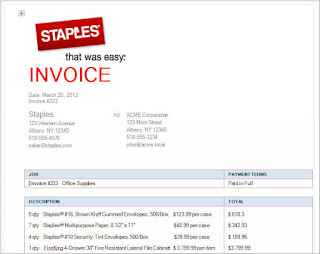
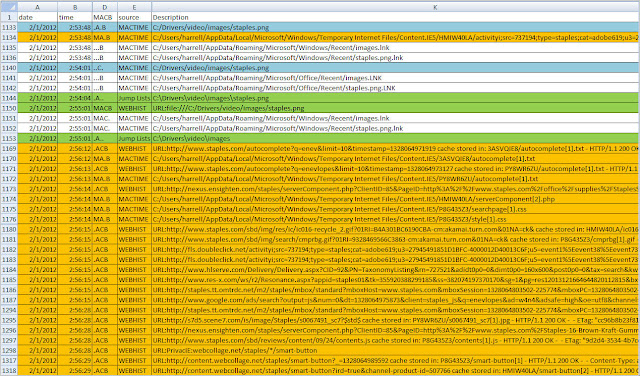
I wanted to briefly mention a few things about the slides. The presentation is meant to compliment the information I’ve been blogging about in regards to Ripping VSCs. In my Ripping VSCs posts I outlined why the approach is important, how it works, and examples showing anyone can start applying the technique to their casework. I now want to put the technique into context by showing how it might apply to an examination. Numerous types of examinations are interested in what a user was doing on a computer so talking about tracking someone’s activities should be applicable to a wider audience. To help explain put the approach into context I created a fake fraud case study to demonstrate how VSCs provide a more complete picture about what someone did on a computer. The presentation will be a mixture of slides with live demos against a live Windows 7 system. Below are the demos I have lined up (if I am short on time then the last demo is getting axed):
- Previewing VSCs with Shadow Explorer
- Listing VSCs and creating symbolic links to VSCs using vsc-parser
- Parsing the link files in a user profile across VSCs using lslnk-directory-parse2.pl
- Parsing Jump Lists in a user profile across VSCs using Harlan’s jl.pl
- Extracting a Word document’s metadata across VSCs using Exiftool
- Extracting and viewing a Word document from numerous VSCs using vsc-parser and Microsoft Word
I’m not covering everything in the slides but I purposely added additional information so the slides could be used as a reference. One example is the code for the batch scripts. Lastly, I’m working on my presentation skills so please lower your expectations. :)![]()
I wanted to briefly mention a few things about the slides. The presentation is meant to compliment the information I’ve been blogging about in regards to Ripping VSCs. In my Ripping VSCs posts I outlined why the approach is important, how it works, and examples showing anyone can start applying the technique to their casework. I now want to put the technique into context by showing how it might apply to an examination. Numerous types of examinations are interested in what a user was doing on a computer so talking about tracking someone’s activities should be applicable to a wider audience. To help explain put the approach into context I created a fake fraud case study to demonstrate how VSCs provide a more complete picture about what someone did on a computer. The presentation will be a mixture of slides with live demos against a live Windows 7 system. Below are the demos I have lined up (if I am short on time then the last demo is getting axed):
- Previewing VSCs with Shadow Explorer
- Listing VSCs and creating symbolic links to VSCs using vsc-parser
- Parsing the link files in a user profile across VSCs using lslnk-directory-parse2.pl
- Parsing Jump Lists in a user profile across VSCs using Harlan’s jl.pl
- Extracting a Word document’s metadata across VSCs using Exiftool
- Extracting and viewing a Word document from numerous VSCs using vsc-parser and Microsoft Word
I’m not covering everything in the slides but I purposely added additional information so the slides could be used as a reference. One example is the code for the batch scripts. Lastly, I’m working on my presentation skills so please lower your expectations. :)